REST: A Stress-Testing Framework for Evaluating Multi-Problem Reasoning in Large Reasoning Models
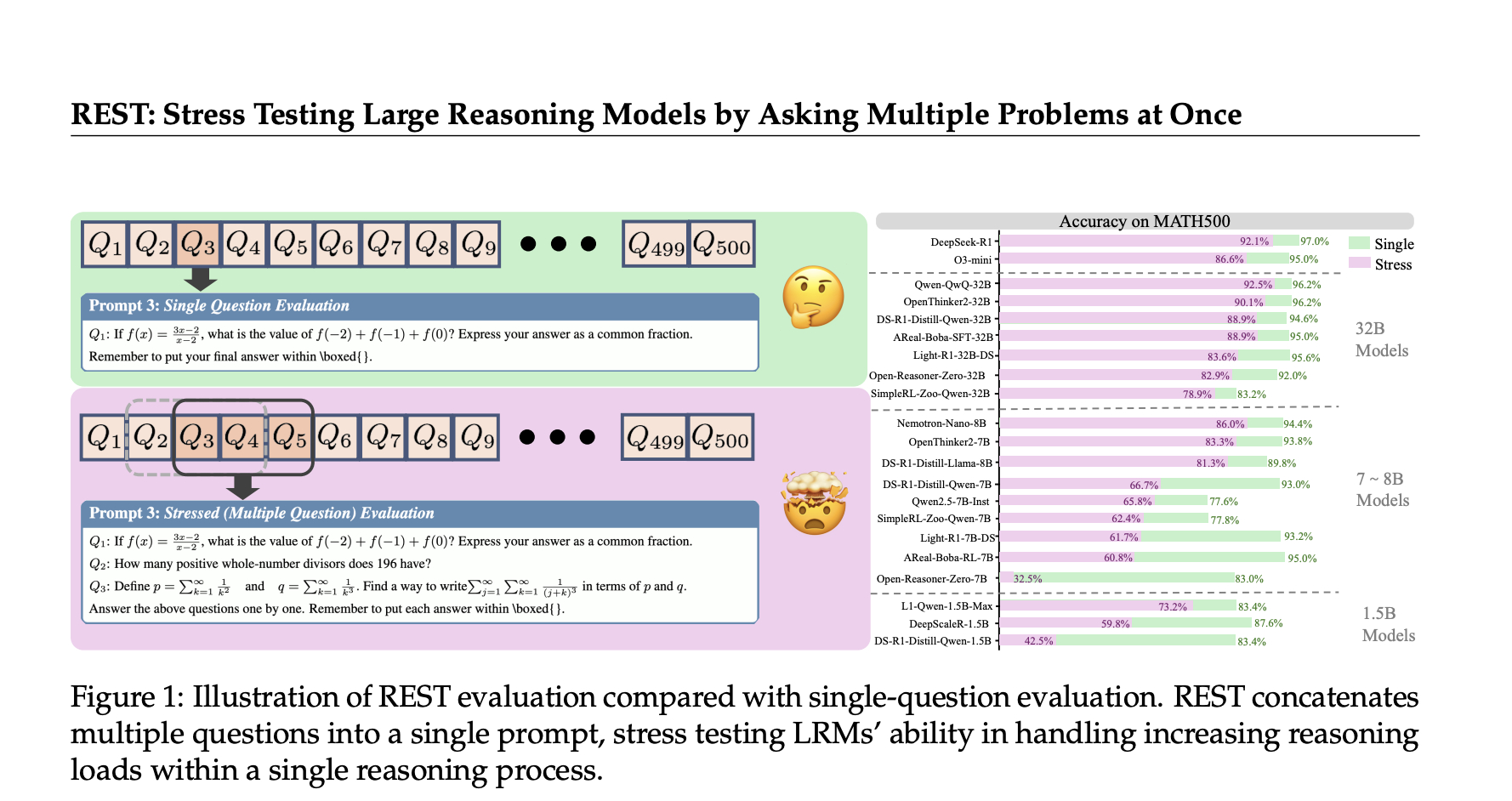


Large Reasoning Models (LRMs) have rapidly advanced, exhibiting impressive performance in complex problem-solving tasks across domains like mathematics, coding, and scientific reasoning. However, current evaluation approaches primarily focus on single-question testing, which reveals significant limitations. This article introduces REST (Reasoning Evaluation through Simultaneous Testing) — a novel multi-problem stress-testing framework designed to push LRMs beyond isolated problem-solving and better reflect their real-world multi-context reasoning capabilities.
Why Current Evaluation Benchmarks Fall Short for Large Reasoning Models
Most current benchmarks, such as GSM8K and MATH, evaluate LRMs by asking one question at a time. While effective for initial model development, this isolated question approach faces two critical drawbacks:
- Decreasing Discriminative Power: Many state-of-the-art LRMs now achieve near-perfect scores on popular benchmarks (e.g., DeepSeek-R1 reaching 97% accuracy on MATH500). These saturated results make it increasingly difficult to distinguish true model improvements, forcing the expensive, continuous creation of harder datasets to differentiate capabilities.
- Lack of Real-World Multi-Context Evaluation: Real-world applications — like educational tutoring, technical support, or multitasking AI assistants — require reasoning across multiple, potentially interfering questions simultaneously. Single-question testing does not capture these dynamic, multi-problem challenges that reflect true cognitive load and reasoning robustness.
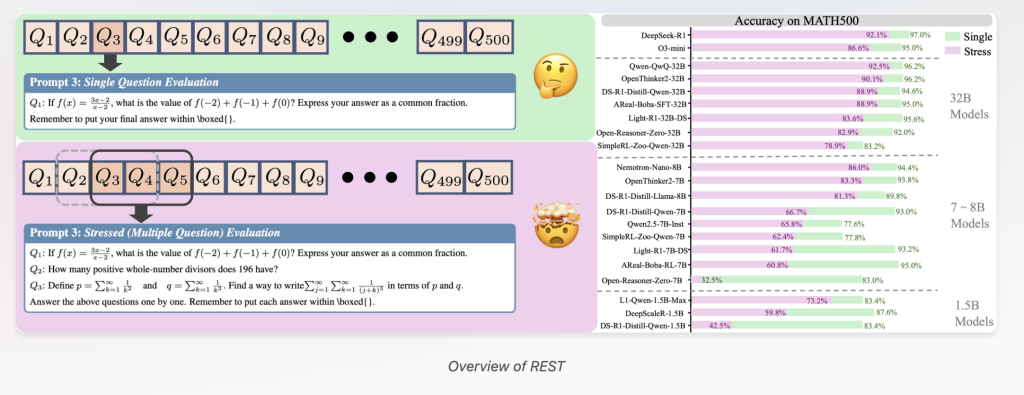
Introducing REST: Stress-Testing LRMs with Multiple Problems at Once

To address these challenges, researchers from Tsinghua University, OpenDataLab, Shanghai AI Laboratory, and Renmin University developed REST, a simple yet powerful evaluation method that simultaneously tests LRMs on multiple questions bundled into a single prompt.
- Multi-Question Benchmark Reconstruction: REST repurposes existing benchmarks by concatenating multiple questions into one prompt, adjusting the stress level parameter that controls how many questions are presented simultaneously.
- Comprehensive Evaluation: REST evaluates critical reasoning competencies beyond basic problem-solving — including contextual priority allocation, cross-problem interference resistance, and dynamic cognitive load management.
- Wide Applicability: The framework is validated on 34 advanced LRMs ranging from 1.5 billion to 671 billion parameters, tested on 7 diverse benchmarks across varying difficulty levels (from simple GSM8K to challenging AIME and GPQA).
REST Reveals Key Insights About LRM Reasoning Abilities
The REST evaluation uncovers several groundbreaking findings:
1. Significant Performance Degradation Under Multi-Problem Stress
Even state-of-the-art LRMs like DeepSeek-R1 show notable accuracy drops when handling multiple questions together. For example, DeepSeek-R1’s accuracy on challenging benchmarks like AIME24 falls by nearly 30% under REST compared to isolated question testing. This contradicts prior assumptions that large language models are inherently capable of effortlessly multitasking across problems.
2. Enhanced Discriminative Power Among Similar Models
REST dramatically amplifies the differences between models with near-identical single-question scores. On MATH500, for instance:
- R1-7B and R1-32B achieve close single-question accuracies of 93% and 94.6%, respectively.
- Under REST, R1-7B’s accuracy plummets to 66.75% while R1-32B maintains a high 88.97%, revealing a stark 22% performance gap.
Similarly, among same-sized models like AReaL-boba-RL-7B and OpenThinker2-7B, REST captures significant differences in multi-problem handling abilities that single-question evaluations mask.
3. Post-Training Methods May Not Guarantee Robust Multi-Problem Reasoning
Models fine-tuned with reinforcement learning or supervised tuning on single-problem reasoning often fail to preserve their advantages in REST’s multi-question setting. This calls for rethinking training strategies to optimize reasoning robustness under realistic multi-context scenarios.
4. “Long2Short” Training Enhances Performance Under Stress
Models trained with “long2short” techniques — which encourage concise and efficient reasoning chains — maintain higher accuracy under REST. This suggests a promising avenue for designing models better suited to simultaneous multi-problem reasoning.
How REST Stimulates Realistic Reasoning Challenges
By increasing the cognitive load on LRMs through simultaneous problem presentation, REST simulates real-world demands where reasoning systems must dynamically prioritize, avoid overthinking one problem, and resist interference from concurrent tasks.
REST also systematically analyzes error types, revealing common failure modes such as:
- Question Omission: Ignoring later questions in a multi-question prompt.
- Summary Errors: Incorrectly summarizing answers across problems.
- Reasoning Errors: Logical or calculation mistakes within the reasoning process.
These nuanced insights are largely invisible in single-question assessments.
Practical Evaluation Setup and Benchmark Coverage
- REST evaluated 34 LRMs spanning sizes from 1.5B to 671B parameters.
- Benchmarks tested include:
- Simple: GSM8K
- Medium: MATH500, AMC23
- Challenging: AIME24, AIME25, GPQA Diamond, LiveCodeBench
- Model generation parameters are set according to official guidelines, with output token limits of 32K for reasoning models.
- Using the standardized OpenCompass toolkit ensures consistent, reproducible results.

Conclusion: REST as a Future-Proof, Realistic LRM Evaluation Paradigm
REST constitutes a significant leap forward in evaluating large reasoning models by:
- Addressing Benchmark Saturation: Revitalizes existing datasets without expensive full replacements.
- Reflecting Real-World Multi-Task Demands: Tests models under realistic, high cognitive load conditions.
- Guiding Model Development: Highlights the importance of training methods like Long2Short to mitigate overthinking and encourage adaptive reasoning focus.
In sum, REST paves the way for more reliable, robust, and application-relevant benchmarking of next-generation reasoning AI systems.
Check out the Paper, Project Page and Code. All credit for this research goes to the researchers of this project. SUBSCRIBE NOW to our AI Newsletter

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
